ビューは実表からselect文で作成された仮想表である。
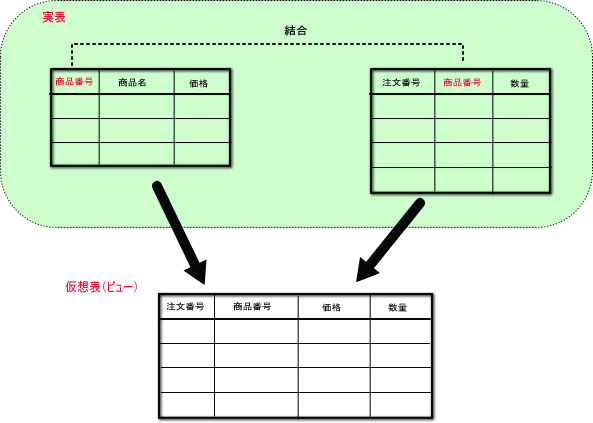
上記は、
2つの実表を、 商品番号フィールドで結合して、1つの表にした
例である。
(2005.11.29更新)
先週に引き続き、SQLServerで実習を行う。
今回SQLサーバに接続するための ID と パスワード は、 先回用いたものと同じものである。
1つあるいは幾つかのテーブルを組み合わせてSELECT文で作成した一時的な表のことをビューと呼ぶ。
| データベースで実際にレコードを記録するテーブルを実表と呼ぶ。 ビューは実表からselect文で作成された仮想表である。 上記は、 2つの実表を、 商品番号フィールドで結合して、1つの表にした 例である。 |
・Accessでは、いつもの手順どおり選択クエリーを作成すればよい。 選択クエリーは、SQLのSelectを実行するクエリーである。つまり、選択クエリーを実行したときに表示される表がビューに相当する。
クエリーによるビューに名前を与え、他のクエリからテーブルとして参照することが出来る。
Accessでは、選択クエリーに付けた名前がビューの名前になり、他のクエリーからその名前で参照できるようになる。
・SQLServerでビューに名前を付けて保存しておくには、以下の構文を用いる。
CREATE VIEW ビューの名前 (表示項目,....) AS SELECT文
AS以下には以前に解説したSELECT文を書くことが出来る。
()の部分は、AS以下のSELECTの実行の結果、得られる表に()内で指定したフィールド名を付け直して、新たなフィールド名を与える為の項目である。
select や delet や update などで、FROMキーワードで表名を指定する代わりに、ビューを指定することができる。
データベースの利用時に実際に表示したり印刷する表は、実はビューである場合が多い。
では、なぜ、ビューをテーブル(実表)として最初からDBMSに用意しないのだろうか?
ビューは次のような場合に必要となる。
・テーブルの正規化により分割されたテーブルを元のテーブルに戻るように結合して表示する
・テーブルを利用者の用途に応じて必要な部分だけ表示する
もし、データベースマネジメントシステム(DBMS)中に、予め必要となるテーブルを実表として全て用意しておくと、データの重複を生じ無駄であるばかりでなくデータの追加・更新・削除においても非常に手間を生じる。
そこで、DBMS中には必要最小限の実表だけを用意し、実表以外のテーブルが必要な場合はビューとしてその都度クエリーで実表から組み立てなおして表示する方が良い解決法となる。
このように、利用時とデータの格納時で別々にデータを扱うために考案されたのが、3層スキーマと呼ばれるDBMSの構造である。
3層スキーマ構造:
DBMSを設計する際の基本的概念。DBMSを運用する際には、各スキーマ間で独立性が保たれていることが望ましい。
| (ユーザー側) | 外部スキーマ(ビュー) | 概念スキーマ RDBMSでは、テーブルとリレーション |
内部スキーマ | (ハードウェア側) |
| 職員:履修登録(記録・修正) 学生:自分の成績表(表示のみ) 教員:担当科目成績表(記録・修正) |
開講科目表(科目ID、担当者、開講日時、教室) 科目表(科目ID、科目名、単位数、種別) 学籍簿(学籍番号、氏名) 履修表(履修時期、科目ID、担当者、学籍番号、成績) 教員表(氏名、所属、研究室) |
ディスクドライブ ファイル ネットワーク セキュリティ バックアップ 検索システム(インデックス) |
各スキーマの独立性が高い場合、以下の利点がある。
・データベースの設計者は、DBMSがどの様なプログラムから出来ているか(内部スキーマ)、言い換えればDBMSのソフトの種類によらず、データベースを構築できる。
⇒上の表でいうと、RDBMSであれば、どのDBMSを利用してもテーブルとリレーションという概念でデータベースを設計できる。
・データベースの利用者は、どの様にデータベースが表現されているか(概念スキーマ)を意識せずにデータベースを利用できる。
⇒上の表でいうと、ユーザはクエリーで予め用意されたビューを利用するだけでよく、テーブルの構造を意識しなくて済む。
例)
MS-ACCESSで製作された成績処理DBMSがWindowsマシンのC:ドライブに存在するとする。
SQLサーバに接続し、以下を行う。
演習室PCとは別の場所にあるSQLサーバにネットワークで接続し、サーバー上のデータベースで共同作業を行う。
osql -S cyteen -U アカウント
use db???????
go
学籍簿を作成する
create table STUDENT ( ID integer, NAME char(12) )go
番号1、名前1は自分のものを利用する。名前には漢字を利用できる(ALT+半角全角キー)
insert into STUDENT values ( 番号1, '名前1' )
go
insert into STUDENT values ( 番号2, '名前2' )go
create table CLASS ( CLASS_ID integer, NAME char(12) )
go
insert into CLASS values ( 1, 'DataBase' )
go
履修表を作成する
create table STUDIES ( ID integer, CLASS_ID integer)go
自分の番号で、科目番号1の科目の履修を記録する
insert into STUDIES values ( 番号, 1 )
go
| create view STUDY_LIST (name , class) as select student.name, class.name from student, studies, class where student.id=studies.id and studies.class_id=class.class_id |
| 実表 | STUDENT
|
CLASS
|
STUDIES
|
||||||||||||
| ビュー | STUDY_LIST
|
||||||||||||||
インデックス機能は、例えて言うと、データベース中のデータに見出し(目次)を付け、データの検索効率を上げるような仕組みのこと。
データベースには、大量のデータを効率よく処理するために、データの検索を高速で行う仕組みが必要である。
データ検索の高度なアルゴリズムを利用できるようにあらかじめDBMSにはインデックスと呼ばれる機能が用意されている。
データベースの設計者は、このアルゴリズムそのものを理解していなくても、処理の効率化を図るためにインデックスを利用することができる。
テーブルのフィールドに対してインデックスを設定すると、検索などの効率を上げることができる。
解説ページを用意したので時間があるときに参照しておくこと。
SQLサーバに接続し、インデックスを設定した場合の効果を確認する。
インデックス利用上の方針:
・ 単なるデータ記録用のテーブルには、データベースはインデックスを必要としない。
データの検索や並べ替えに利用しないフィールドについて、インデックスを作成しても無駄(インデックスの作成と構造の再編の負荷が増すだけ)だからである。
・ ある程度の規模のテーブルの、頻繁に参照されるフィールドに対してインデックスを設定すると処理の効率が改善される。
STUDENT表のIDフィールドにINDEXを設定することで、IDを利用したデータベースの処理効率が改善される。
ここまでで製作したデータ数ではインデックスの効果を測定するには少なすぎるので、大量のデータに対して処理を行わせてindexの効果を測定してみる。
処理内容:
・20000個のデータの処理にかかる時間の計測
| declare @a as int set @a = @@cpu_busy select num from rand group by num having count(num)>3 print cast( @@cpu_busy - @a as char(2)) + 'ms' |
変数宣言 実行前のCPU消費時間を記録 CPU消費時間を表示 |
| declare @a as int set @a = @@cpu_busy select num from rand group by num having count(num)>3 print cast( @@cpu_busy - @a as char(2)) + 'ms' |
変数宣言 実行前のCPU消費時間を記録 CPU消費時間を表示 |
ここまでで演習は終了です。